CGRAMの中身の話だよ。
データシートの図をコピペすればよいのではと思うこともあるけども、横着してDS読みに行かない人が出たらどうしようと考えてしまって出来ていないniszetですこんにちは。
さて、このお話も4回目、折り返しです(まだ折り返しか…)
前回の記事
niszet.hatenablog.com
CGRAMはどのように字形を保存しているか
PLCDは文字領域が16x2あるキャラクタ液晶ディスプレイで、各文字は横5dot縦8dotで構成され、CGRAMに外字を登録するということで、今回はCGRAMの中身についての話です。
データシートの17ページ目に書いてあることが全てではあるのですが、ここでは改めてサンプルコードも交えて説明します。
液晶の各ドットのオン/オフによって字形を表現することが出来ます。このオン/オフの状態を数字の1と0にそれぞれ割り当てることでプログラム内で扱うことが出来ます。1と0の状態を表現するデータのことをbit、8bitをまとめたものを1byteと呼んだりしますね。
CGRAMでは行ごとにアドレスを付けていて、上から0,1,2 ... と 7までの8つが与えられています。この行方向にデータをまとめてあげて、それを縦8つ分まとめてあげればCGRAM用のデータの出来上がりです。行単位で1byte、これが8列あって1つも文字分の表示領域の字形データの表現に8byte必要という計算になります。
実際の液晶画面は横に5ドット分しかないので、行方向の1byteのデータのうち上位3bit分は使用されず下位の5bitだけが使われます。この領域にデータを書き込んでも画面の表示に変更はありません。
データを詰め詰めにして5byteにすることも可能でしょうが、このLCDではそうなっていませんね。もちろんそういう実装もありでしょうし、縦方向にすることも考えられますね。でも扱いも煩雑になるので使う側としてはやめてほしいけども。
話がそれたぞ。
Arduinoで(…に限らず、CやC++で)最小単位のデータ型はchar型で1byte、8bitになります。組み込み用のプログラムだと使用できるメモリ量がとても少ないのでデータ量は少しでも減らしておきたいことから、char型をよく使います。今回も丁度良いですね。
サンプルコードではchar cg0[8] ... の8つの配列です。配列の話は…まぁいいか。データの並びを表現するためのものです(割愛)
1点注意としては、このcgなんたらは画面表示のために使いますが、これがCGRAMそのものではないです。CGRAMにこの値を反映するためにはサンプルコードで言うところのplcd_cgram関数で書き込むことが必要です。
さて、そのCGRAMに字形情報を登録する関数、plcd_cgram()ですが今は関数内部実装には立ち入らないことにして、引数(関数に渡しているパラメータ)の意味だけ押さえておきましょう。
定義をみると、
void plcd_cgram(char adr, char *d, int len)
で、それぞれ
- adr : 文字コードアドレス(外字を登録するDDRAMの文字アドレス。指定できるのは0-7の8つ)
- *d : char型のポインタ…ここではcg0みたいなデータ列を受け取るもの、までの理解で行きましょう。ポインタの説明は面倒くさいので。
- len : 配列の長さ。cg0たちはcg0[8]のように全部で8要素入っているので8を与えます。
です。具体的な呼び出し方は
plcd_cgram(0, cg0, 8);
こんな感じで、文字アドレス0にchar型の配列cg0のデータが送られ、それは要素数が8ですよ、と伝えていますね。この関数を実行するたびに文字アドレス0にcg0で設定したデータが書き込まれます。
では、cg0のデータについて見ていきましょうか。
char cg0[8] = {0x04, 0x04, 0x04, 0x1f, 0x00, 0x0e, 0x00, 0x04};
0x00みたいな書き方は0xがこれは16進数の表記だよという接頭辞で、うしろの2文字が16進数で2文字で0から255までを表します。10がA、11がB、12がC、13がD、14がE、15がFで0x00-0xFFまでの表現、最大値は16x15+15=255。
配列にデータを与えて初期化する場合は{}で囲います。この辺りはC/C++の文法の話だしいいか。
ここでそれぞれの16進数が10進数で何を表しているか見てもいいんですけど、実際にはこれは液晶の各ドットのON/OFFを便宜的に1と0であらわしたものを束ねているだけなのであまり意味はないです。よって割愛。
逆?に、これらが液晶のドットとどのように対応しているのかを見ましょう。cg0のそれぞれの16進数をbit(2進数)形式であらわすと、それぞれ
8'b0000_0100
8'b0000_0100
8'b0000_0100
8'b0001_1111
8'b0000_0000
8'b0000_1110
8'b0000_0000
8'b0000_0100
となります。頭の8は8bitだよという意味、bはバイナリ(binary、2進数、bitでもいいのかな?)、_は見やすさのための区切りで意味はないです。
0と1で書くとうっすら字形が見える気がしますね?
では実際にお絵かきしてみます。ここでは万能方眼紙であるエクセルを使って描いていますが、エクセルは本来(以下省略)
一応、下に10進数の値も書いてみました。Cって12だから8と4で…1100だな…みたいに計算するために使ってください(?)
cg0の字形は…
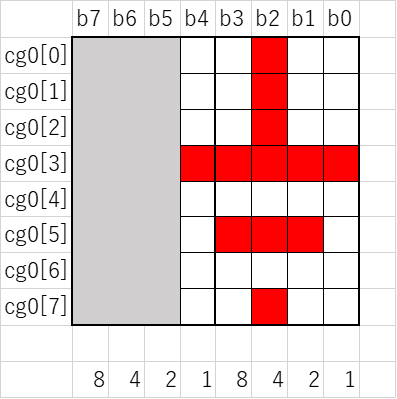
サンプルコード下にある写真の左上の図形と一致しましたね!
ということで、CGRAMにどういうデータを入れればどういう字形が表示されるのかがわかりましたね。もちろん、CGRAMにデータを書き込むだけでは液晶画面に表示されないので、サンプルコードのplcd_cgramで字形データを送った後のplcd_dataで文字コードを所定の座標に書き込むことが必要です。
plcd_cmd(0x80 | 0);
for (int i = 0; i < 8; i++) {
plcd_data(i);
plcd_data(' ');
}
このコードでは最初に書き込むためのカーソル位置を0,0に設定し、順に文字コードを0から7まで(8は含まれないので注意)書き込んでいますね。DDRAMに文字を書きこんだらカーソルが1つ後ろにずれるので、これは文字コード0、空白を書き込んで次のループ、文字コード1、空白を書き込んで次のループ…でひとつずつ右に書き込む座標がずれていきます。結果として、CGRAMに登録した図形が1文字おきに表示され、サンプルコード下の写真のように表示されるのでした。
気になる人はCGRAMの他の字形データも写真のようになってるか確認してみましょう。
ということで、CGRAMに字形を書き込んで液晶に表示するまでの話が一通り終わります。
次回、ようやく文字列がスクロールします。長かった…。
察しの良い人はもう気づいている気もしますが…
次の記事
niszet.hatenablog.com










